You are viewing the RapidMiner Radoop documentation for version 9.4 - Check here for latest version
Distribution-specific Notes
For certain Hadoop distributions, you may need to complete additional client-side configuration using the Connection Settings dialog. Cluster modifications usually need an SSH connection or access to a Hadoop management tool (for example, Cloudera Manager or Ambari). You may need to contact your Hadoop administrator to perform the cluster configuration steps.
Connecting to a CDH 5.13 Quickstart VM
Start and configure the Quickstart VM
-
Download the Cloudera Quickstart VM (version 5.13) from the Cloudera website.
-
Import the OVA packaged VM to your virtualization environment (Virtualbox and VMware are covered in this guide).
-
It is strongly recommended to upgrade to Java 1.8 on the single-node cluster provided by the VM. Otherwise, the execution of Single Process Pushdown and Apply Model operators will fail.
You can take the following steps only if no clusters or Cloudera management services have been started yet. For the full upgrading process, read Cloudera’s guide.
Upgrading to Java 1.8:
- Start the VM.
- Download and unzip JDK 1.8 – preferrably jdk1.8.0_60 – to
/usr/java/jdk1.8.0_60. -
Add the following configuration line to
/etc/default/cloudera-scm-server:export JAVA_HOME=/usr/java/jdk1.8.0_60 - Launch Cloudera Express (or Enterprise trial version).
-
Open a web browser, and log in to Cloudera Manager (
quickstart.cloudera:7180) usingcloudera/clouderaas credentials. Navigate to Hosts / quickstart.cloudera / Configuration. In Java Home Directory field, enter/usr/java/jdk1.8.0_60 - On the home page of Cloudera Manager, (re)start the Cloudera QuickStart cluster and Cloudera Management Service as well.
-
If you are using Virtualbox, make sure that the VM is shut down, and set the type of the primary network adapter from NAT to Host-only. The VM will work only with this setting in a Virtualbox environment.
-
Start the VM and wait for the boot to complete. A browser with some basic information will appear.
-
Edit your local
hostsfile (on your host operating system, not inside the VM) and add the following line (replace<vm-ip-address>with the IP address of the VM):<vm-ip-address> quickstart.cloudera
Setup the connection in RapidMiner Studio
-
Click on
 New Connection button and choose
New Connection button and choose  Add Connection Manually
Add Connection Manually -
Set Hadoop username to
hive. (As an alternative, you can set both Hadoop username and Username on Hive tab to your own user.) -
Add
quickstart.clouderaas NameNode Address -
Add
quickstart.clouderaas Resource Manager Address -
Add
quickstart.clouderaas Hive Server Address -
Select Cloudera Hadoop (CDH5) as Hadoop version
-
Add the following entries to the Advanced Hadoop Parameters:
Key Value dfs.client.use.datanode.hostnametrue(This parameter is not required when using the Import Hadoop Configuration Files option):
Key Value mapreduce.map.java.opts-Xmx256m -
Select the appropriate Spark Version (this should be Spark 1.6 if you want use the VM’s built-in Spark assembly jar) and set the Assembly Jar Location to the following value:
local:///usr/lib/spark/lib/spark-assembly.jar
Connecting to a 3.0.1+ Sandbox VM
Start and configure the Sandbox VM
-
Download the Hortonworks Sandbox VM for VirtualBox (version 3.0.1+) from the Hortonworks website.
-
Import the OVA packaged VM to your virtualization environment (Virtualbox is covered in this guide).
-
Start the VM. After powering it on, you have to select the first option from the boot menu, then wait for the boot to complete.
-
Log in to the VM. You can do this by switching to the login console (Alt+F5), or even better via SSH on localhost port
2122. It is important to note that there are 2 exposed SSH ports on the VM, one belongs to the VM itself (2122), while the other (2222) belongs to a Docker container running inside the VM. The username isroot, the password ishadoopfor both. - Edit the
/sandbox/proxy/generate-proxy-deploy-script.shby include the following ports in thetcpPortsHDParray 8025, 8030, 8050, 10020, 50010.vi /sandbox/proxy/generate-proxy-deploy-script.sh-
Find
tcpPortsHDPvariable, leaving the other values in place, add to the hashtable assignment:[8025]=8025 [8030]=8030 [8050]=8050 [10020]=10020 [50010]=50010
- Run the edited generate-proxy-deploy-script.sh via
/sandbox/proxy/generate-proxy-deploy-script.sh- This will re-create the /sandbox/proxy/proxy-deploy.sh script along with config files in /sandbox/proxy/conf.d and /sandbox/proxy/conf.stream.d, thus exposing the additional ports added to the
tcpPortsHDPhashtable in previous step.
- This will re-create the /sandbox/proxy/proxy-deploy.sh script along with config files in /sandbox/proxy/conf.d and /sandbox/proxy/conf.stream.d, thus exposing the additional ports added to the
- Run the /sandbox/proxy/proxy-deploy.sh script via
/sandbox/proxy/proxy-deploy.sh- Running the
docker pscommand, will show an instance named sandbox-proxy and the ports it has exposed. The inserted values to thetcpPortsHDPhashtable should be shown in the output, looking like 0.0.0.0:10020->10020/tcp.
- Running the
-
These changes only made sure that the referenced ports of the Docker container are accessible on the respective ports of the VM. Since the network adapter of the VM is attached to NAT, these ports are not accessible from your local machine. To make them available you have to add the port forwarding rules listed below to the VM. In VirtualBox you can find these settings under Machine / Settings / Network / Adapter 1 / Advanced / Port Forwarding.
Name Protocol Host IP Host Port Guest IP Guest Port resourcetracker TCP 127.0.0.1 8025 8025 resourcescheduler TCP 127.0.0.1 8030 8030 resoucemanager TCP 127.0.0.1 8050 8050 jobhistory TCP 127.0.0.1 10020 10020 datanode TCP 127.0.0.1 50010 50010 -
Edit your local
hostsfile (on your host operating system, not inside the VM), addsandbox.hortonworks.comandsandbox-hdp.hortonworks.comto your localhost entry. At the end it should look something like this:127.0.0.1 localhost sandbox.hortonworks.com sandbox-hdp.hortonworks.com -
Reset Ambari access. Use an SSH client to login to localhost as root, this time using port
2222! (For example, on OS X or Linux, use the commandssh root@localhost -p 2222, password:hadoop)- (At first login you have to set a new root password, do it and remember it.)
- Run
ambari-admin-password-resetas root user. - Provide a new admin password for Ambari.
- Run
ambari-agent restart.
-
Open the Ambari website:
http://sandbox.hortonworks.com:8080- Login with
adminand the password you chose in the previous step. - Navigate to the YARN / Configs / Memory configuration page.
- Edit the Memory Node Setting to at least 7 GB and click Override.
- User will be prompted to create a new “YARN Configuration Group”, enter a new name.
- On the “Save Configuration Group” dialog, click the Manage Hosts button.
- On the “Manage YARN Configuration Groups page” take the node in the “Default” group and add the node into the group created in the “YARN Configuration Group” name step.
- “Warning” Dialog will open requesting adding notes click the Save button.
- “Dependent Configurations” dialog will open with Ambari providing recommendations to modify some related properties automatically. If so, untick
tez.runtime.io.sort.mbto keep its original value. Click the Ok button.- Ambari may open a “Configurations” page suggesting stuff. Review accordingly, but this is out of the scope of this document, so just click Proceed Anyway.
- Navigate to the Hive / Configs / Advanced configuration page.
-
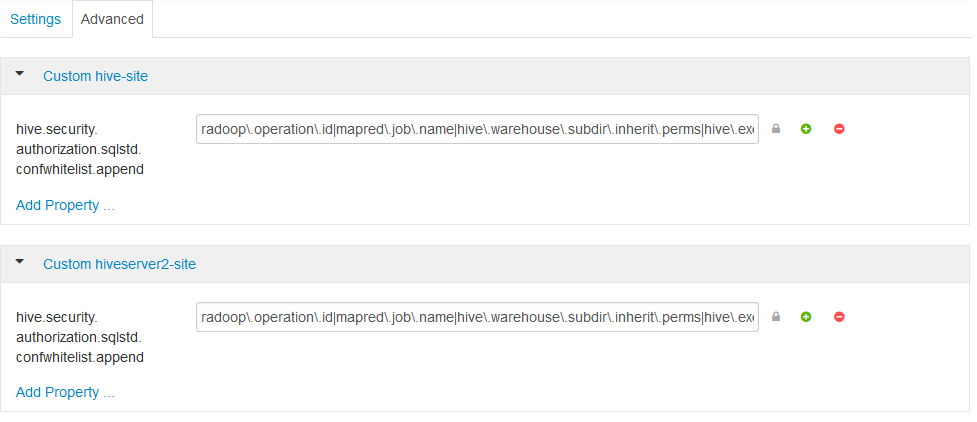
In the Custom hiveserver2-site section. The
hive.security.authorization.sqlstd.confwhitelist.appendneeds to be added via the Add Property… and be set to the following (it must not contain whitespaces):radoop\.operation\.id|mapred\.job\.name|hive\.warehouse\.subdir\.inherit\.perms|hive\.exec\.max\.dynamic\.partitions|hive\.exec\.max\.dynamic\.partitions\.pernode|spark\.app\.name|hive\.remove\.orderby\.in\.subquery - Save the configuration and restart all affected services. More details on
hive.security.authorization.sqlstd.confwhitelist.appendcan be found in Hadoop Security/Configuring Apache Hive SQL Standard-based authorization section.
- Login with
Setup the connection in RapidMiner Studio
-
Click on
New Connection button and choose  Import from Cluster Manager option to create the connection directly from the conifguration retrieved from Ambari.
Import from Cluster Manager option to create the connection directly from the conifguration retrieved from Ambari. - On the Import Connection from Cluster Manager dialog enter
- Cluster Manager URL:
http://sandbox-hdp.hortonworks.com:8080 - Username:
admin - Password: password used in Reset Amabari step.
- Cluster Manager URL:
-
Click Import Configuration
- Hadoop Configuration Import dialog will open up
- If successful click Next button and Connection Settings dialog will open.
- If failed click Back button and review above steps and logs to solve issue(s).
-
On the Connection Settings Dialog, which opens when Next button is clicked from step above.
-
Connection Name can stay defaulted or be changed by user.
- Global tab
- Hadoop Version should be
Hortonworks HDP 3.x - Set Hadoop username to
hadoop.
- Hadoop Version should be
- Hadoop tab
- NameNode Address should be
sandbox-hdp.hortonworks.com - NameNode Port should be
8020 - Resource Manager Address should be
sandbox-hdp.hortonworks.com - Resource Manager Port should be
8050 - JobHistory Server Address should be
sandbox-hdp.hortonworks.com - JobHistory Server Port should be
10020 -
Advanced Hadoop Parameters add the following parameters:
Key Value dfs.client.use.datanode.hostnametrue(This parameter is not required when using the Import Hadoop Configuration Files option):
Key Value mapreduce.map.java.opts-Xmx256m
- NameNode Address should be
- Spark tab
- Spark Version select
Spark 2.3 (HDP) - Check Use default Spark path
- Spark Version select
- Hive tab
- Hive Version should be
HiveServer3 (Hive 3 or newer) - Hive High Availability should be checked
- ZooKeeper Quorum should be
sandbox-hdp.hortonworks.com:2181 - ZooKeeper Namespace should be
hiverserver2 - Database Name should be
default - JDBC URL Postfix should be empty
- Username should be
hive - Password should be empty
- UDFs are installed manually and Use custom database for UDFs are both unchecked
- Hive on Spark/Tez container reuse should be checked
- Hive Version should be
-
Click OK button, the Connection Settings dialog will close
- User can test the connection created above onn Manage Radoop Connections page select the connection created and clicking the Quick Test and
 Full Test… buttons.
Full Test… buttons.
If errors occur durning testing confirm that necessary Components are started correctly at http://localhost:8080/#/main/hosts/sandbox-hdp.hortonworks.com/summary.
It is highly recommended to use ![]() New Connection /
New Connection / ![]() Import from Cluster Manager option to create the connection directly from the configuration retrieved from Cloudera Manager. If you do not have a Cloudera Manager account that has access to the configuration, an administrator should be able to Download Client Configuration. Using the client configuration files, choose
Import from Cluster Manager option to create the connection directly from the configuration retrieved from Cloudera Manager. If you do not have a Cloudera Manager account that has access to the configuration, an administrator should be able to Download Client Configuration. Using the client configuration files, choose ![]() New Connection /
New Connection / ![]() Import Hadoop Configuration Files to create the connection from those files.
Import Hadoop Configuration Files to create the connection from those files.
If security is enabled on the cluster, make sure you check Configuring Apache Sentry authorization section of the Hadoop Security chapter.
Configuring Spark
If you are using Spark 1.6 version you may need to select Spark 1.6 (CDH) for more recent CDH 5.x Cloudera Hadoop releases and Spark 1.6 for older CDH 5.x releases. Select any of them and then run the Spark job test (enable only this test in ![]() Full Test… /
Full Test… / ![]() Customize…) that automatically detects the proper version for you. Please choose the setting that this test recommends.
Customize…) that automatically detects the proper version for you. Please choose the setting that this test recommends.
Using any other Spark version should be straightforward.
The following describes setup for HDP 2.5.0, 2.6.0, 3.0 and 3.1. Setup for other HDP versions should be similar.
Configuring the cluster
If there are restrictions on Hive commands on your cluster (for example, SQL Standard Based Hive Authorization is enabled on it), then the change of certain properties through HiveServer2 must be explicitly enabled. This is required if you get the following error message when running a Full Test in RapidMiner Radoop: Cannot modify radoop.operation.id at runtime. In this case a property must be added on the Ambari interface to resolve this issue.
- Login to the Ambari interface.
- Navigate to the Hive / Configs / Advanced configuration page
- Add the
hive.security.authorization.sqlstd.confwhitelist.appendsetting as a new property to both Custom hive-site and Custom hiveserver2-site. The value should the following (it must contain no whitespaces):radoop\.operation\.id|mapred\.job\.name|hive\.warehouse\.subdir\.inherit\.perms|hive\.exec\.max\.dynamic\.partitions|hive\.exec\.max\.dynamic\.partitions\.pernode|spark\.app\.name
- Save the configuration and restart the proposed services.
For a more detailed explanation, see the Hadoop security section.
To enable Spark operators in RapidMiner Radoop, make the following changes in the Connection Settings dialog:
-
Select the appropriate Spark Version option in the Spark Settings. If Spark is installed with Ambari, the Spark Version depends on the cluster’s HDP version.
HDP version Spark assembly JAR location 3.1.x Spark 2.3 (HDP) 3.0.x Spark 2.3 (HDP) 2.6.x Spark 1.6 or Spark 2.1 / Spark 2.2 2.5.x Spark 1.6 or Spark 2.0 -
Set the Assembly Jar Location / Spark Archive path to point to the Spark location on your cluster. The following table contains the default local locations depending on your HDP version. Refer to your Hadoop administrator if the specified path does not seem to work.
HDP version Spark 1.x assembly JAR location Spark 2.x archive path 3.1.x local:///usr/hdp/current/spark2-client/jars/3.0.x local:///usr/hdp/current/spark2-client/jars/2.6.x local:///usr/hdp/current/spark-client/lib/spark-hdp-assembly.jarlocal:///usr/hdp/current/spark2-client/jars/2.5.x local:///usr/hdp/current/spark-client/lib/spark-hdp-assembly.jar
Notes on security
If you receive a permission error during connection Full Test, verify that:
- The
/user/<hadoop_username>directory exists on the HDFS and is owned by <hadoop_username>. (If the Hadoop username setting is empty, the client OS username is used.) - The <hadoop_username> has write privileges on
/user/historydirectory on the HDFS.
SQL Standard Based Hive Authorization may require that the user running HiveServer2 owns the files and directories loaded into Hive. This can disrupt the normal operation of RapidMiner Radoop. In case of a permission error, consult your Hadoop administrator.
Connecting to an Azure HDInsight 3.6 cluster using Radoop Proxy
RapidMiner Radoop supports version 3.6 of Azure HDInsight, a cloud-based Hadoop service that is built upon Hortonworks Data Platform (HDP) distribution. If RapidMiner Radoop does not run inside the Azure network, there are a couple of options for the networking setup. A solution like Azure ExpressRoute or a VPN can simplify the setup. However, if those options are not available, the HDInsight clusters can be accessed using Radoop Proxy, which coordinates all the communication between RapidMiner Studio and the cluster resources. Since this setup is the most complex, this guides assumes this scenario, feel free to skip steps that are not required because of an easier networking setup.
For a proper networking setup, a RapidMiner Server instance (with Radoop Proxy enabled) should be installed on an additional machine that is located in the same virtual network as the cluster nodes. The following guide provides the necessary steps for establishing a proxied connection to an HDInsight cluster.
Starting an HDInsight cluster
If you already have an HDInsight cluster running in the Azure network, skip these steps entirely.
-
Create a new Virtual network for all the network resources that will be created during cluster setup. The default Address space and Subnet address range may be suitable for this purpose. Use the same Resource group for all resources that are created during the whole cluster setup procedure.
-
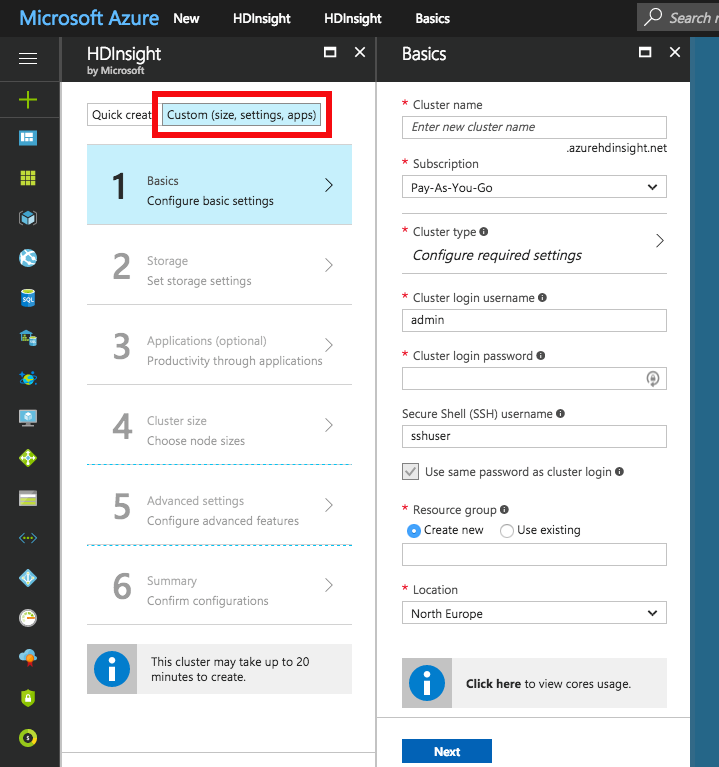
Use the Custom (size, settings, apps) option instead of Quick create for creating the cluster. Choose Spark cluster type with Linux operating system, and the latest Spark version supported by Radoop, which is Spark 2.2.0 (HDI 3.6) as of this writing. Fill all the required login credential fields. Select the previously defined Resource group.
-
Choose the Primary storage type of the cluster. You may specify additional storage accounts as well.
- Azure Storage : Provide a new or already existing Storage account and a Default container name. You may connect to as many Azure Storage accounts as needed.
- Data Lake Store : Provide a Data Lake Store account. Make sure that the root path exists and the associated Service principal has adequate privileges for accessing the chosen Data Lake Store and path. Please note that a Service principal can be re-used for other cluster setups as well. For this purpose, it is recommended to save the Certificate file and the Certificate password for future reference. Once a Service principal is chosen, the access rights for any Data Lake Stores can be configured via this single Service principal object.
-
Configure the Cluster size of your choice.
-
On Advanced settings tab, choose the previously created Virtual network and Subnet.
-
After getting through all the steps of the wizard, create the cluster. After it has started, please find the private IPs and private domain names of the master nodes. You will need to copy these to your local machine. This step is required because some domain name resolutions need to take place on the client (RapidMiner Studio) side. The easiest way to do this is by copying it from one of the cluster nodes. Navigate to the dashboard of your HDInsight cluster, and select the SSH + Cluster login option. Choose any item from the Hostname selector. On Linux and Mac systems you can use the ssh command appearing below the selector. On Windows systems you will have to extract the hostname and the username from the command, and use PuTTY to connect to the host. The password is the one you provided in step 2. Once you are connected, view the contents of the /etc/hosts file of the remote host, for example by issuing the following command:
cat /etc/hosts. Copy all the entries with long, generated hostnames. Paste them into the hosts file of your local machine, which is available at the following location:- For Windows systems: Windows\system32\drivers\etc\hosts
- For Linux and Mac systems: /etc/hosts
Starting RapidMiner Server and Radoop Proxy
-
Create a new RapidMiner Server virtual machine in Azure. For this you will need to select the “Create a resource” option and search the Marketplace for RapidMiner Server. Select the BYOL version which best matches your Studio version. Press Create and start configuring the virtual machine. Provide the Basic settings according to your taste, but make sure that you use the previously configured Resource group and the same Location as for your cluster. Click Ok, then select a virtual machine size with at least 10GB of RAM. Configure optional features. It is essential that the same Virtual network and Subnet are selected in the Network settings as the ones used for the cluster. All other settings may remain unchanged. Check the summary, then click Create.
-
Once the VM is started, you still need to wait a few minutes for RapidMiner Server to start. The easiest way to validate this is to open (Public IP address of the VM):8080 in your browser. Once that page loads, you can log in with admin username and the name of your VM in Azure as password. You will immediately be asked for a valid license key. A free license is perfectly fine for this purpose. If your license is accepted you can close this window, you will not need it anymore.
Setting up the connection in RapidMiner Studio
First, create a Radoop Proxy Connection for the newly installed Radoop Proxy (described here in Step 1). The needed properties are:
| Field | Value |
|---|---|
| Radoop Proxy server host | Provide the IP address of the MySQL server instance. |
| Radoop Proxy server port | The value of radoop_proxy_port in the used RapidMiner Server install configuration XML (1081 by default). |
| RapidMiner Server username | admin (by default) |
| RapidMiner Server password | name of Azure proxy VM (by default) |
| Use SSL | false (by default) |
For setting up a new Radoop connection to an Azure HDInsight 3.6 cluster, we strongly recommend to choose ![]() Import from Cluster Manager option, as it offers by far the easiest way to make the connection work correctly.
This section describes the Cluster Manager import process. The Cluster Manager URL should be the base URL of the Ambari interface web page (e.g.
Import from Cluster Manager option, as it offers by far the easiest way to make the connection work correctly.
This section describes the Cluster Manager import process. The Cluster Manager URL should be the base URL of the Ambari interface web page (e.g. https://radoopcluster.azurehdinsight.net). You can easily access it by clicking Ambari Views on the cluster dashboard.
After the connection is imported, most of the required settings are filled automatically. In most cases, only the following properties have to be provided manually:
| Field | Value |
|---|---|
| Advanced Hadoop Parameters | Disable the following properties: io.compression.codec.lzo.class and io.compression.codecs |
| Hive Server Address | This is only needed, if you do not use the ZooKeeper service discovery (Hive High Availability is unchecked). Can be found on Ambari interface (Hive / HiveServer2). In most cases, it is the same as the NameNode address. |
| Radoop Proxy Connection | The previously created Radoop Proxy Connection should be chosen. |
| Spark Version | Select the version matching the Spark installation on the cluster, which is Spark 2.2 if you followed above steps for HDInsight install. |
| Spark Archive (or libs) path | For Spark 2.2 (with HDInsight 3.6), the default value is (local:///usr/hdp/current/spark2-client/jars). Unless using a different Spark version you are fine with leaving Use default Spark path checkbox selected. |
| Advanced Spark Parameter | Create spark.yarn.appMasterEnv.PYSPARK_PYTHON property with a value of /usr/bin/anaconda/bin/python. |
You will also need to configure your storage credentials, which is described by the Storage credentials setup section. If you want to connect to a premium cluster you will need to follow the steps in the Connecting to a Premium cluster section. Once you completed these steps, you can click OK on the Connection Settings dialog, and save your connection.
It is essential that the RapidMiner Radoop client can resolve the hostnames of the master nodes. Follow the instructions of Step 6 of the Starting an HDInsight cluster to add these hostnames to your operating system’s hosts file.
Storage credentials setup
An HDInsight cluster can have more storage instances attached, which may even have different storage types (Azure Storage and Data Lake Store). For accessing them, the related credentials must be provided in Advanced Hadoop Parameters table. The following sections clarify the type of credentials needed, and how they can be acquired.
It is essential that the credentials of the primary storage are provided.
You may have multiple Azure Storages attached to your HDInsight cluster, provided that any additional storages were specified during cluster setup. All of these have access key(s) which can be found at Access keys tab on the storage dashboard. To enable access towards an Azure Storage, provide this key as an Advanced Hadoop Parameter:
| Key | Value |
|---|---|
fs.azure.account.key.<storage_name>.blob.core.windows.net |
the storage access key |
As above mentioned, a single Active Directory service principal object can be attached to the cluster. This controls the access rights towards Data Lake Store(s). Obviously, only one Data Lake Store can take the role of the primary storage. In order to enable Radoop to access a Data Lake Store through this principal, the following Advanced Hadoop Parameters have to be specified:
| Key | Value |
|---|---|
dfs.adls.oauth2.access.token.provider.type |
ClientCredential |
dfs.adls.oauth2.refresh.url |
OAuth 2.0 Token Endpoint address |
dfs.adls.oauth2.client.id |
Service principal application ID |
dfs.adls.oauth2.credential |
Service principal access key |
You can acquire all of these values under Azure Active Directory dashboard (available at the service list of the main Azure Portal). Click App registrations on the dashboard, then look for the needed values as follows:
- For OAuth 2.0 Token Endpoint address, go to Endpoints, and copy the value of OAuth 2.0 Token Endpoint.
- On App registrations page, choose the Service principal associated with your HDInsight cluster, and provide the value of Application ID as Service principal application ID.
- Click Keys. Generate a new key by entering a name and an expiry date, and replace the value of Service principal access key with the generated password.
Finally, go to the HDInsight cluster main page, and click Data Lake Store access in the menu. Provide the value of Service Principal Object ID as Hadoop Username.
Connecting to a Premium cluster (having Kerberos enabled)
If you have set up or have a Premium HDInsight cluster (subscription required), some additional connection settings are required for Kerberos-based authentication.
- Configuring Kerberos authentication section describes general Kerberos-related settings.
- As for all Hortonworks distribution based clusters, you also have to apply a Hive setting (
hive.security.authorization.sqlstd.confwhitelist.append) described in this section. Please note that a Hive service restart will be needed. - We strongly advise to use Import from Cluster Manager option for creating a Radoop connection to the Kerberized cluster. The import process covers some necessary changes in Advanced Hadoop Parameters that are required for the connection to work as expected.
There are multiple options to connect to an EMR cluster
- If RapidMiner Radoop does not run inside the EMR cluster’s connected VPC:
- via SOCKS proxy
- via VPN
- via Radoop Proxy (Recommended)
- Direct access (eg: using Amazon WorkSpaces)
The following steps follow Radoop Proxy recommendation, but you can also find step-by-step guides of the additional steps for other two remote methods below. For direct access setup please follow the Radoop Proxy guide but skip the parts describing the setup of the Radoop Proxy itself.
Connecting to a firewalled EMR cluster using Radoop Proxy
The following steps will guide you through starting and configuring an EMR cluster, and accessing it from RapidMiner Radoop via a RapidMiner Radoop Proxy that is running on the EMR cluster’s Master Node.
-
If you doesn’t already have a running EMR cluster, then use the advanced options on AWS Console for creating your EMR cluster. Select a 5.x version for EMR release. Make sure that Hadoop, Hive and Spark are selected for installation in the Software Configuration step. Complete the rest of the configuration steps on AWS Console, then start the cluster.
-
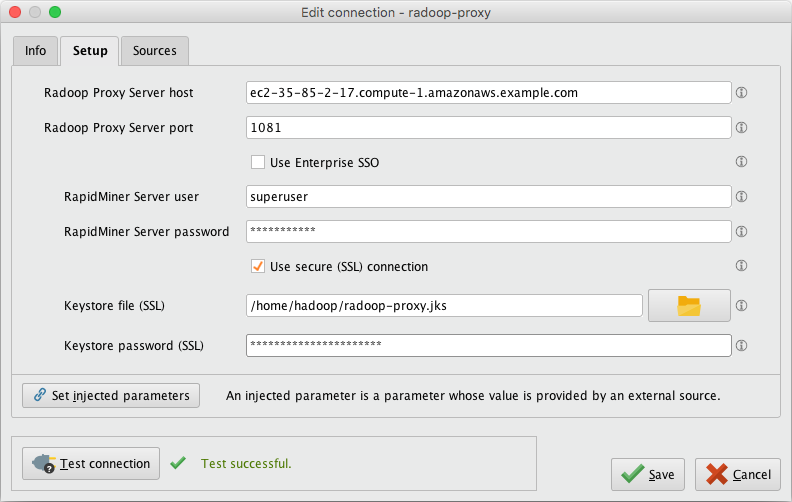
SSH onto the Master node (once its status became either
RUNNINGorWAITINGon the EMR page of the AWS console) SSH instructions can be found on the Summary tab of your EMR cluster. Make note of the <Master public DNS name>, this will be needed later for the Radoop Proxy configuration in RapidMiner Studio. (eg:ec2-35-85-2-17.compute-1.amazonaws.example.com) -
Obtain the internal IP address of the Master node (e.g.
10.1.2.3) via thehostname -icommand and make note of it as this will be needed for the Radoop Connection. (Private IP and DNS information can also be obtained from the AWS Console on the EMR Cluster details page in the Hardware section checking the “EC2 Instances”) -
Perform the following commands to setup Spark on the cluster for Radoop. For Spark 2.x versions, the best practice is to upload the compressed Spark jar files to HDFS from the preinstalled location from the master node. (This is crucial as EMR usually installs relevant libraries onto the file system of the master node only, whereas worker nodes also depend on them) On recent versions of EMR 5.x all of this can easily be done by issuing the following commands on the EMR master node:
#Setup Spark 2.* libraries from the default install location cd /usr/lib/spark zip /tmp/spark-jars.zip --junk-paths --recurse-paths ./jars hdfs dfs -mkdir -p /user/spark hdfs dfs -put /tmp/spark-jars.zip /user/spark #Copy PySpark libaries onto hdfs hdfs dfs -put ./python/lib/py4j-src.zip /user/spark hdfs dfs -put ./python/lib/pyspark.zip /user/spark #Copy SparkR libaries onto hdfs hdfs dfs -put ./R/lib/sparkr.zip /user/spark #List all the files that have been put onto hdfs in the /user/spark directory hdfs dfs -ls /user/sparkIf everything went well the output should be very similar to this:
[hadoop@ip-172-31-18-147 spark]$ hdfs dfs -ls /user/spark Found 4 items -rw-r--r-- 1 hadoop spark 74096 2019-07-25 17:47 /user/spark/py4j-src.zip -rw-r--r-- 1 hadoop spark 482687 2019-07-25 17:48 /user/spark/pyspark.zip -rw-r--r-- 1 hadoop spark 180421304 2019-07-25 17:47 /user/spark/spark-jars.zip -rw-r--r-- 1 hadoop spark 698696 2019-07-25 17:48 /user/spark/sparkr.zip
-
Follow the instructions in the Standalone Radoop Proxy section. Start the Radoop Proxy after the configuration has been completed.
-
Start RapidMiner Studio and create a New Radoop Proxy connection. Use the <Master public DNS name> (from step 2) as the Radoop Proxy Server host. Make sure to test the Proxy connection via the Test Connection button.
-
In RapidMiner Studio create a new Radoop Connection with the following values (you can supply additional configuration parameters as needed). Advanced Radoop users can alternatively import the connection template below which includes all required settings listed in this table.
Property Value Hadoop Version Amazon Elastic MapReduce (EMR) 5.x Hadoop username hadoop NameNode Address <Master node internal IP address from step 3> (e.g. 10.1.2.3)NameNode Port 8020 Resource Manager Address <Master node internal IP address from step 3> (e.g. 10.1.2.3)Resource Manager Port 8032 JobHistory Server Address <Master node internal IP address from step 3> (e.g. 10.1.2.3)Hadoop Advanced Parameters Add key/value dfs.client.use.datanode.hostnamevalue offalseSpark Version Corresponding Spark version (eg: Spark 2.3.1+)Use custom PySpark archive Checked Custom PySpark archive paths Add two entries hdfs:///user/spark/py4j-src.zipandhdfs:///user/spark/pyspark.zipUse custom SparkR archive Checked Custom SparkR archive path hdfs:///user/spark/sparkr.zipHive Server Address <Master node internal IP address from step 3> (e.g. 10.1.2.3)Hive Username hive Use Radoop Proxy Checked Radoop Proxy Connection <Select the Proxy created in step 6> Note Please consider fine tuning Spark memory settings as discussed here.
<?xml version="1.0" encoding="UTF-8"?><radoop-connection-entry>
<name>Amazon EMR Connection Example</name>
<compatibilityLevel>9.4.0</compatibilityLevel>
<masterAddress/>
<jobtrackerAddress><Master node internal IP address eg 10.1.2.3></jobtrackerAddress>
<namenodeAddress><Master node internal IP address eg 10.1.2.3></namenodeAddress>
<jobHistoryServerAddress><Master node internal IP address eg 10.1.2.3></jobHistoryServerAddress>
<hiveserverAddress><Master node internal IP address eg 10.1.2.3></hiveserverAddress>
<multipleMasterAddress>T</multipleMasterAddress>
<hiveDB>default</hiveDB>
<hivePort>10000</hivePort>
<mapredPort>8032</mapredPort>
<hdfsPort>8020</hdfsPort>
<jobHistoryServerPort>10020</jobHistoryServerPort>
<hiveHighAvailability>F</hiveHighAvailability>
<zookeeperQuorum/>
<zookeeperNamespace/>
<hadoopVersion>hadoop-emr-5.x</hadoopVersion>
<useDefaultPorts>F</useDefaultPorts>
<useRadoopProxy>T</useRadoopProxy>
<securityEnabled>F</securityEnabled>
<retrievePrincipalsFromHive>T</retrievePrincipalsFromHive>
<realm/>
<kdc/>
<krbConfFile/>
<saslQopLevel>auth</saslQopLevel>
<hivePrincipal/>
<jobHistoryServerPrincipal/>
<keytabFile/>
<usekerberospassword>F</usekerberospassword>
<kerberospassword/>
<impersonation>F</impersonation>
<sparkVersion>SPARK_23_1</sparkVersion>
<useCustomPySparkLocation>T</useCustomPySparkLocation>
<useCustomSparkRLocation>T</useCustomSparkRLocation>
<customPySparkLocation>hdfs:///user/spark/pyspark.zip,hdfs:///user/spark/py4j-src.zip</customPySparkLocation>
<customSparkRLocation>hdfs:///user/spark/sparkr.zip</customSparkRLocation>
<sparkAssemblyJar>hdfs:///user/spark/spark-jars.zip</sparkAssemblyJar>
<sparkResourceAllocationPolicy>dynamic</sparkResourceAllocationPolicy>
<sparkHeuristicAllocationPercentage>30</sparkHeuristicAllocationPercentage>
<advancedHadoopSettings>
<keyvalueenabledelement>
<key>dfs.client.use.datanode.hostname</key>
<valuee>false</valuee>
<enabled>T</enabled>
</keyvalueenabledelement>
</advancedHadoopSettings>
<advancedHiveSettings/>
<advancedSparkSettings>
<keyvalueenabledelement>
<key>spark.driver.extraJavaOptions</key>
<valuee>-XX:+PrintGC -XX:+PrintGCDateStamps</valuee>
<enabled>T</enabled>
</keyvalueenabledelement>
<keyvalueenabledelement>
<key>spark.driver.memory</key>
<valuee>2000</valuee>
<enabled>T</enabled>
</keyvalueenabledelement>
<keyvalueenabledelement>
<key>spark.executor.extraJavaOptions</key>
<valuee>-XX:+PrintGC -XX:+PrintGCDateStamps</valuee>
<enabled>T</enabled>
</keyvalueenabledelement>
<keyvalueenabledelement>
<key>spark.executor.memory</key>
<valuee>2000Mb</valuee>
<enabled>T</enabled>
</keyvalueenabledelement>
<keyvalueenabledelement>
<key>spark.logConf</key>
<valuee>true</valuee>
<enabled>T</enabled>
</keyvalueenabledelement>
</advancedSparkSettings>
<libdir/>
<hadoopusername>hadoop</hadoopusername>
<hiveusername>hive</hiveusername>
<hiveversion>hive2</hiveversion>
<hivepassword/>
<manuallyinstalledudfs>F</manuallyinstalledudfs>
<usecustomudfdatabase>F</usecustomudfdatabase>
<customudfdatabase/>
<hiveurlpostfix/>
<hivejdbc>hive_0.13.0</hivejdbc>
<execframework>yarn</execframework>
<accesswhitelist>*</accesswhitelist>
<forceproxyonserver>F</forceproxyonserver>
<useContainerPool>T</useContainerPool>
</radoop-connection-entry>
- Save the Radoop Connection and perform Quick/Full Tests accordingly.
A different Hadoop username can be used, but please check that the username is created and has proper permissions and ownership rights on the /user/<username> directory on HDFS via hdfs dfs -ls /user.
SOCKS proxy is another option to connect to your EMR cluster. See the Networking Setup section for information on starting a SOCKS proxy and an SSH tunnel. Please open the SSH tunnel and the SOCKS proxy.
Setup the connection in RapidMiner Studio
-
Select Amazon Elastic MapReduce (EMR) 5.x as the Hadoop version.
-
Set the following addresses:
- NameNode Address: <master_private_ip_address> (e.g.
10.1.2.3) - Resource Manger Address: <master_private_ip_address> (e.g.
10.1.2.3) - JobHistory Server Address: <master_private_ip_address> (e.g.
10.1.2.3) - Hive Server Address:
localhost
- NameNode Address: <master_private_ip_address> (e.g.
-
Set the ports if necessary
- Set Hive port to 1235 (as described in Networking Setup)
-
Add the following Advanced Hadoop Parameters key-value pair (as described in Networking Setup):
Key Value dfs.client.use.legacy.blockreadertruehadoop.rpc.socket.factory.class.defaultorg.apache.hadoop.net.SocksSocketFactoryhadoop.socks.serverlocalhost:1234 -
Save the Radoop Connection and perform Quick/Full Test accordingly.
EMR VPN is another option to connect to your EMR cluster. This will require setting up a dedicated EC2 instance with the VPN software.
Setting up the VPN
If the user already has a VPN established for the EMR cluster then this section can be skipped. But the user does need to still take note of the VPN’s IP address and DNS name and make sure the VPN is attached to the EMR cluster’s VPC and subnet.
-
When the cluster is in a
RUNNINGorWAITINGstate, note the private IPs and private domain names of the EC2 instances should be available. -
Start a VPN server using an EC2 instance in the same VPC as the EMR cluster.
-
Connect to the VPN from your desktop
- Check if the correct route is set up (e.g.
172.30.0.0/16)
- Check if the correct route is set up (e.g.
-
Enable the network traffic from the VPN to the EMR cluster
- On the EMR Cluster details page open the Master (and later the Slave) security group settings page
- At the inbound rules add a new rule and enable “All Traffic” from the VPC network (e.g.
172.30.0.0/16) - Do this setting on both the Master and Slave security groups of the EMR cluster
-
Optional: Setup local hosts file (if you would like to use host/DNS names instead of IP addresses)
- On the EMR Cluster details page in the Hardware section check the “EC2 Instances” and get the private IP and DNS.
- Add the hostnames (DNS) and IP addresses of the nodes to your local hosts file (e.g.
172.30.1.209 ip-172-30-1-209.ec2.local)
Setting up the Radoop Connection in RapidMiner Studio to use the VPN
When the VPN server has been established either by the Setting up the VPN instructions above or by some external entity the Radoop Connection can be created. Use the steps described in the Connecting to a firewalled EMR cluster using Radoop Proxy section skipping the setup requirement for Radoop Proxy itself.
Notes for deprecated distributions
Radoop supports MapR 5.x/6.x for both RapidMiner Studio and RapidMiner Server. Note that MapR support on Server requires RapidMiner Server version 8.1 or later.
Setting up cluster machines
- Make sure that DNS and reverse DNS resolution works on all of the cluster machines even if it is a single node cluster. To achieve such you might as well setup a DNS service or manually edit the
/etc/hostsfile on each node.
Setting up client machine
-
Studio and Server Job Agents must be running on host machines with MapR 5.x or 6.x client installed and connected.
- Depending on the MapR cluster version user will need to follow instructions for installing either MapR 5.x Client or the MapR 6.x Client. Make sure to pick the version corresponding to the cluster.
- Set the following system environment variables properly:
- MAPR_HOME - this is the path to MapR client, on a default installation it would be either
/opt/maprorC:\opt\mapr - HADOOP_HOME - this is the path to MapR Hadoop files on the client, typically will be
${MAPR_HOME}/hadoop/hadoop-x.y.z(withx.y.zbeing the version number of hadoop), this is required on Windows for running Radoop, if not set properly user could see error messages ofERROR util.Shell: Failed to locate winutils binary in the hadoop binary pathwhen establishing connections to the MapR cluster - MAPR_SUBNETS - system environment variable contains the internal subnet of the MapR cluster. More info on MAPR_SUBNETS found here
- Add
${HADOOP_HOME}\binto the system-wide environment variablePATH, if not set properly user could see error messages ofjava.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Zwhen establishing connections to the MapR cluster.
- MAPR_HOME - this is the path to MapR client, on a default installation it would be either
- Double check the content of your
${MAPR_HOME}/conf/mapr-cluster.conffile. Check that all addresses listed are reachable from the client machine. - User setup for insecure clusters
- On OS X or Linux in secure configurations make sure that the user is available on all of the cluster nodes. It can be done on cluster side by creating a new user with an UID which matches the client side. This can be achieved by using the
adduserunix command. - On Windows, edit
${MAPR_HOME}/hadoop/hadoop-x.y.z/etc/hadoop/core-site.xmlto configure the UID, GID and user name of the cluster user that will be used to access the cluster, see Configuring MapR Client User on Windows. This is required for both the MapR 5.x and MapR 6.x client.
- On OS X or Linux in secure configurations make sure that the user is available on all of the cluster nodes. It can be done on cluster side by creating a new user with an UID which matches the client side. This can be achieved by using the
- To confirm the client machine is connected, user should be able to perform the following commands from the command line and get back a valid result. Both the
yarnandhadoopcommands should be accesible, because of the adding of$HADOOP_HOME/binto the system-wide environmentPATH. See MapR Your First Hadoop Job for details. (If the cluster is secure acquiring a MapR ticket viamaprloginmay be required before running the commands.)hadoop fs -ls /should return a file listyarn jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0-mapr-1803.jar pi 10 1000will run a hadoop provided example of a mapreduce job on the cluster calculating Pi. For the result please check application logs in the Job History Server.
-
If your HiveServer2 instance is secured by MapR Security, you need to do additional setup for Hive access. If it is not, this step can be skipped. Copy the jars according to the MapR JDBC Connections docs to a common directory on the host machine. These jars should be available to be copied by from the MapR 5.x/6.x cluster machine with Hive installed typically in the
${MAPR_HOME}/hive/hive-<version>/libdirectory. See an example list below. Note that the files may differ on your environment.
| File name |
|---|
| hive-exec-2.1.1-mapr-<version>.jar |
| hive-jdbc-2.1.1-mapr-<version>.jar |
| hive-metastore-2.1.1-mapr-<version>.jar |
| hive-service-2.1.1-mapr-<version>.jar |
| hive-shims-2.1.1-mapr-<version>.jar |
| httpclient-4.4.jar |
| httpcore-4.4.jar |
| libfb303-0.9.3.jar |
| libthrift-0.9.3.jar |
| log4j-1.2.17.jar |
| In the case of MapR 6.x you may also need: |
| log4j-api-2.4.1.jar |
| log4j-core-2.4.1.jar |
Radoop Connection Setup
In case of a secure cluster, a MapR ticket must always be available when connecting to a secure cluster via Radoop. Refer to maprlogin command documentation for further info.
You must enter accessible hostnames for all server addresses (eg: Hive Address).
Click on ![]() New Connection button and choose
New Connection button and choose ![]() Add Connection Manually
Add Connection Manually
Global tab
-
Choose either MapR 5.x or MapR 6.x for the Hadoop version.
- Please verify the MapR Client Home and MapR Subnets as they are displayed on the dialog as taken from the System environment.
-
Select or Enter the MapR Cluster name in the MapR cluster. This pull down is developed from the
${MAPR_HOME}/conf/mapr-clusters.conffile. If cluster name is not listed here chances are that MapR client wasn’t properly setup in the Setting up client machine section. -
If the Hadoop instance is secured by MapR Security select Enable MapR Security.
Hadoop tab
-
Enter Resource Manager Address and JobHistory Server Address fields.
-
Review default port settings in JobHistory Server Port field.
Spark tab
-
Select the Spark Version according to the installed Spark version on the cluster. If none is installed select None. For more information see Install Spark on Yarn in MapR documentation for cluster installation instructions.
-
You may either Use default Spark path or by unchecking it provide the actual path by editing the Spark Archive (or libs) path textfield.
- Based on the selected Hadoop version, Spark Archive (or libs) path field is defaulted to:
- MapR 5.x –
local:///opt/mapr/spark/spark-2.1.0/jars - MapR 6.x –
local:///opt/mapr/spark/spark-2.2.0/jars
- MapR 5.x –
- The path must be accessible on the cluster and contain the spark artifacts.
- Based on the selected Hadoop version, Spark Archive (or libs) path field is defaulted to:
-
Provide Spark Resource Allocation Policy according to your Spark setup on the cluster.
- Spark Resource Allocation Policy is defaulted to Dynamic Resource Allocation. If the cluster is not configured for this, Spark test will time out and log entries of
InvalidAuxServiceException: The auxService:spark_shuffle does not existwill appear in the logs for the corresponding Spark job. In this case, either change cluster to enable Dynamic Resource Allocation see MapR - Enabling Dynamic Allocation in Apache Spark or change to different Resource Allocation Policy on the Radoop connection (e.g. to Static, Default Configuration).
- Spark Resource Allocation Policy is defaulted to Dynamic Resource Allocation. If the cluster is not configured for this, Spark test will time out and log entries of
-
On Windows, add the following Advanced Spark Parameters entry. Here we assume that the $MAPR_HOME on the cluster is
/opt/mapr, please change the value if this is not the case.Key Value spark.driver.extraClassPath/opt/mapr/hadoop/hadoop-2.7.0/share/hadoop/mapreduce/* - If the MapR Cluster being connected to has High-Availability enabled. You will also have to transpose the contents of the
${HADOOP_HOME}/etc/hadoop/yarn-site.xmlto the Advanced Spark Parameters.
For everypropertyelement present in the${HADOOP_HOME}/etc/hadoop/yarn-site.xmldo the following:- Create a new Advanced Spark Parameter row
- Copy the
nameelement value to theKeyfield appendspark.hadoop.to the value - Copy the
valueelement to theValuefield - Ensure the new row is marked enabled
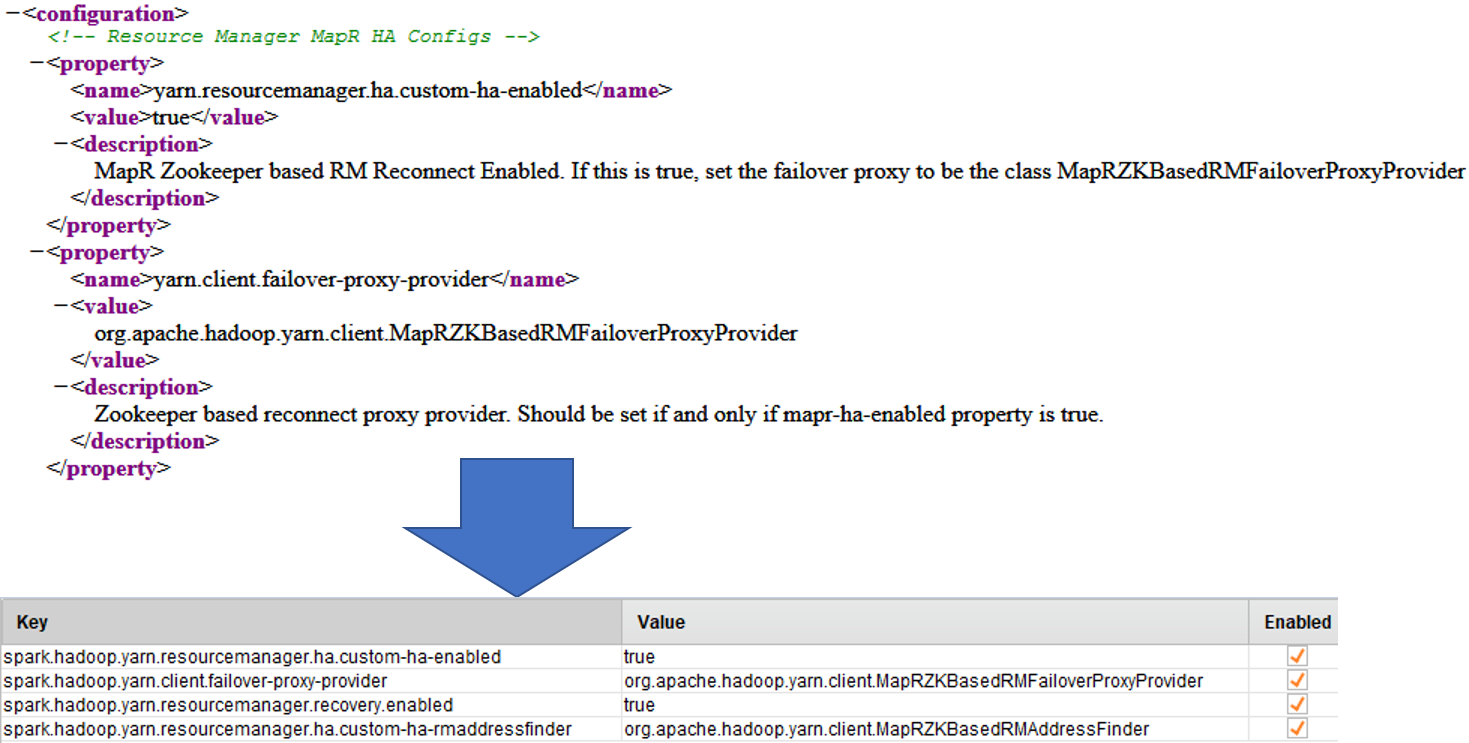
-
At this point Spark settings may look like this.
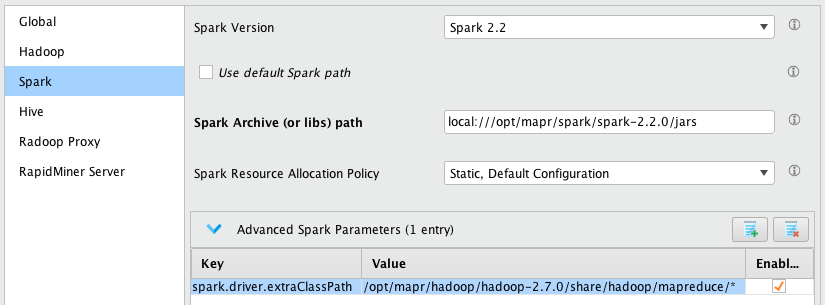
Hive tab
- Depending on security setup of Hive
- If MapR security is not enabled
- For Hive Version select HiveServer2 (Hive 0.13 or newer)
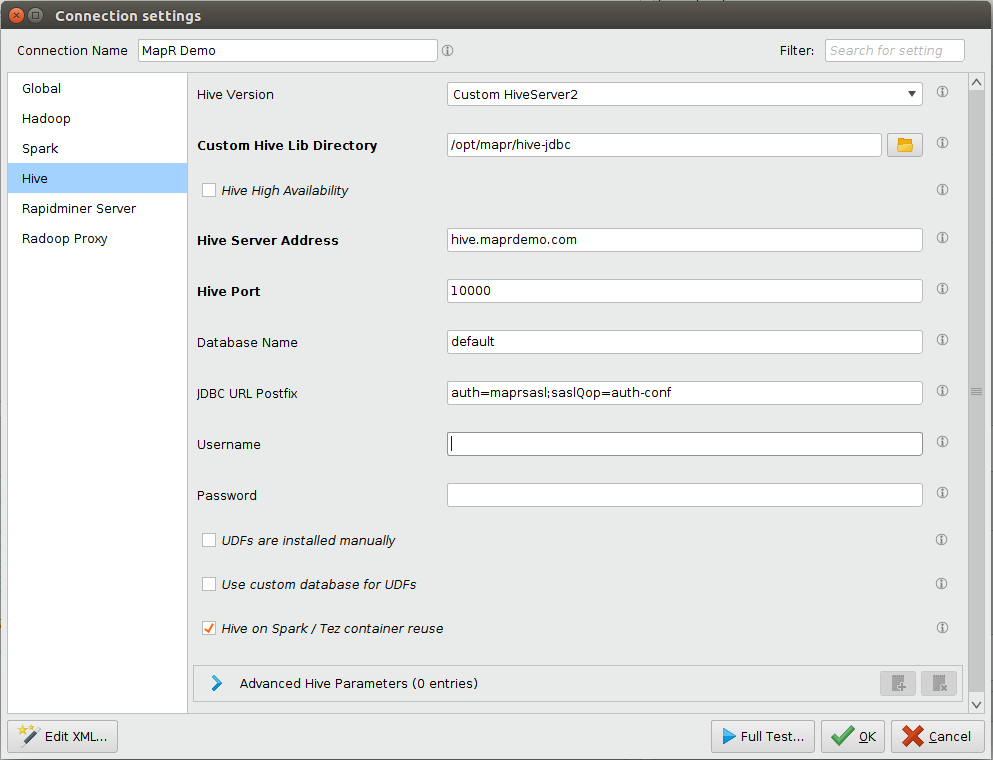
- If your HiveServer2 instance is secured by MapR Security
- For Hive Version select Custom HiveServer2
- In Custom Hive Lib Directory select the directory where jars were copied to in step 2 of Setting up client machine section.
- For JDBC URL Postfix append
auth=maprsasl;saslQop=auth-confto the textfield. If Hive server was setup with SSL then see Hive SSL Setup in Notes
- Additionally if your HiveServer2 instance is secured with SSL it will require a truststore and an optional truststore password. For this user need to adjust the JDBC URL Postfix connection field.
- If truststore is not passed into the running JVM, user will need to append
ssl=true;sslTrustStore=<path-to-truststore>;sslTrustStorePassword=<password> - If the truststore is known by the JVM, user will only need to append
ssl=true. Truststores can be installed to the the JVM either by- Installing trusted MapR certificates into the default Java Keystore.
- Including
-Djavax.net.ssl.trustStore=<path-to-trust-store-file> -Djavax.net.ssl.trustStorePassword=<password>to the Rapidminer Studio/Server JVM startup command.
- If truststore is not passed into the running JVM, user will need to append
- If MapR security is not enabled
-
Enter and verify Hive Address and Hive Port fields.
-
Enter your login credentials in the Hive Username and Hive Password fields. Provided Hive Username must be an existing identity on the cluster. Please note depending on cluster setup these fields can be blank.
-
At this point Hive settings may look like this.
After completing the setup on all of the tabs mentioned above Quick Test and Full Test of the newly created connection should pass without errors.
Notes on configuring user impersonation on Server
For RapidMiner Server, user impersonation makes it possible to act as different users on cluster. The user will always be the actual RapidMiner Server user authenticated by Server. The Server users allowed to access the MapR cluster must therefore exist on the cluster as well.
As the Windows MapR client does not support user impersonation, connecting from RapidMiner Server installed on a Windows machine to a MapR cluster with multiple users is not currently possible.
-
Follow the instructions of the Radoop on Server guide to setup the Radoop connections.
-
Acquire a long-lived MapR ticket that can impersonate other users on all Job Agent hosts. The following commands are just examples, please refer to MapR documentation for more info. Note that you have to make sure that the Job Agents see the MAPR_TICKETFILE_LOCATION environment variable (you may need to modify their startup script for that). Set the file permissions for the generated ticket properly, so that it cannot be accessed by unauthorized users. You may also want to adjust related settings, see settings related to resolving usernames.
maprlogin password maprlogin generateticket -type servicewithimpersonation -out /var/tmp/impersonation_ticket -duration 30:0:0 -renewal 90:0:0 export MAPR_TICKETFILE_LOCATION=/var/tmp/impersonation_ticket
Connecting to an IBM Open Platform (IOP) cluster with default settings usually works without any special setting on the Connection Settings dialog. Select IBM Open Platform 4.1+ as Hadoop version, and provide the appropriate address fields. If the SQL Standard Based Hive Authorization is enabled for your cluster or any unexpected error occurs, please refer to the Hortonworks Data Platform description.